
生物医学大数据中心
智拓健康科技在线平台
菌控e+:基于机器学习的抗食源性致病菌 ssDNA 适配体的虚拟筛选
STEP1:通过(random)随机生成序列
STEP2:通过(expasy)进行数据去冗余
STEP3:通过(pse)或(biotriganle)进行文本转向量并输出CSV文件
STEP4:上传CSV文件并预测结果
虚拟筛选结果
关于我们
MFOLD(基于机器学习的抗沙门氏菌及IBV外毒素的SSDNA适配体的虚拟筛选)是一个用于虚拟筛选的Web服务器,筛选出的适体折叠过程的热力学特性及二维结构进行细致评估,并将所得结果与经过验证的适配体以及必然为非适配体的随机序列进行对比分析。该网络服务器集成了集成机器模型来筛选抗沙门氏菌及IBV外毒素的SSDNA适配体。
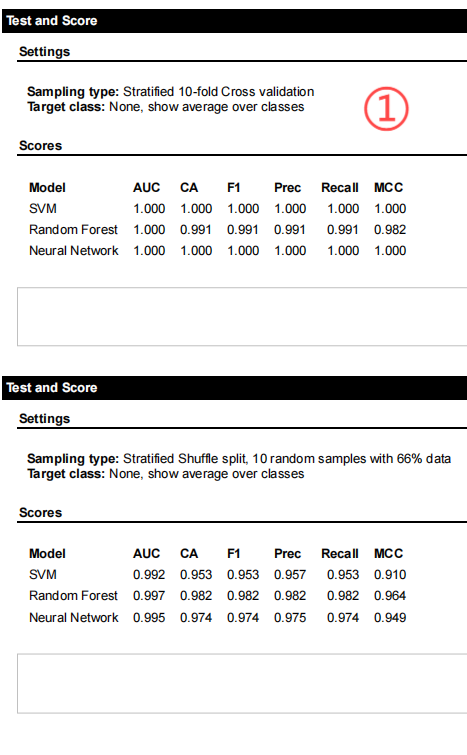
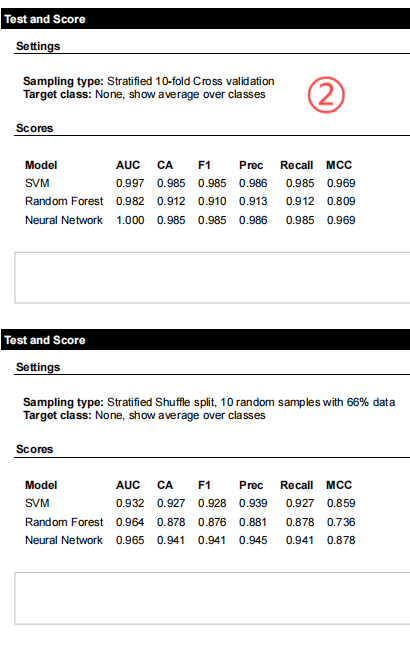
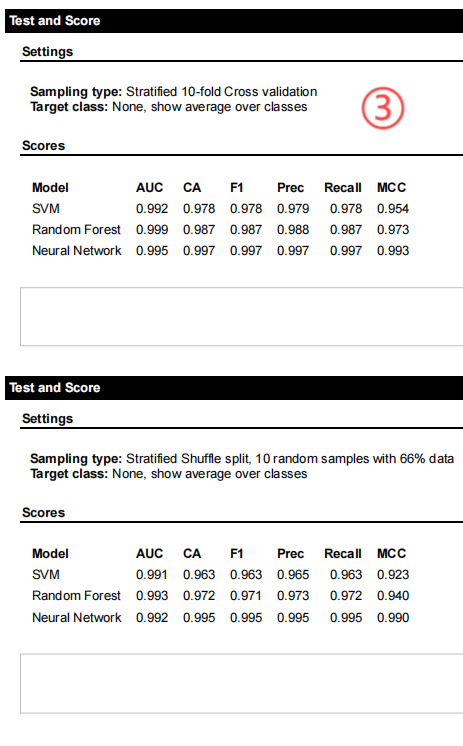
适配体虚拟筛选技术:基于体外选择原理,采用支持向量机(SVM)、随机森林(RF)和人工神经网络(ANN)等多种机器学习算法与PseKNC方法相结合对抗沙门氏菌的SSDNA适配体进行虚拟筛选预测。这种技术为生物医学研究提供了全新的分子识别工具。
适配体预测模型构建与训练:通过收集验证数据、生成随机序列、序列数值化、算法分类、结构建模、模型评价、改进数据大小和模型优化等步骤,构建出高效预测适配体与沙门氏菌结合能力的模型,并进行筛选预测。
Post-SELEX修饰截断法:也称为适配体后筛选,为了得到亲和性更高、特异性更强、序列更短的适配体选择性地截断适配体,进行POST-SELEX法的处理,重新进行评估与原适配体对比。
预测适配体与外毒素分子对接:进一步可视化适配体-蛋白质复合物(外膜靶标-配体复合物),在复合物中寻找与外膜靶标直接相互作用的非转录间隔区(nts),获得最高亲和力的nts。
生物验证:进行虚拟分子对接结果良好地预测适配体进行可视化检测验证的斑点点迹实验进行验证。